Pubmed: Wilbrecht L
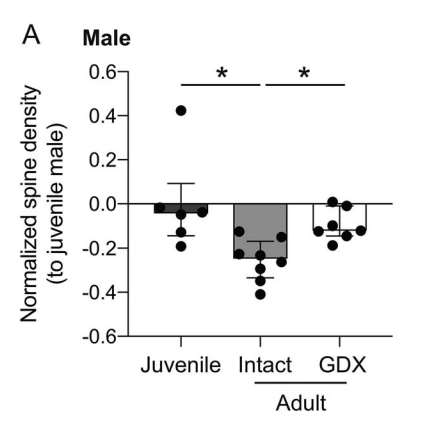
Prepubertal ovariectomy alters dorsomedial striatum indirect pathway neuron excitability and explore/exploit balance in female mice
Decision-making circuits are modulated across life stages (e.g. juvenile, adolescent, or adult)—as well as on the shorter timescale of reproductive cycles in females—to meet changing environmental and physiological demands. Ovarian hormonal modulation of relevant neural circuits is a potential mechanism by which behavioral flexibility is regulated in females. Here we examined the influence of prepubertal ovariectomy (pOVX) versus sham surgery on performance in an odor-based multiple choice reversal task. We observed that pOVX females made different types of errors during reversal learning compared to sham surgery controls. Using reinforcement learning models fit to trial-by-trial behavior, we found that pOVX females exhibited […]
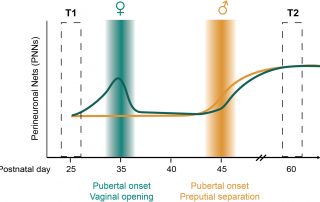
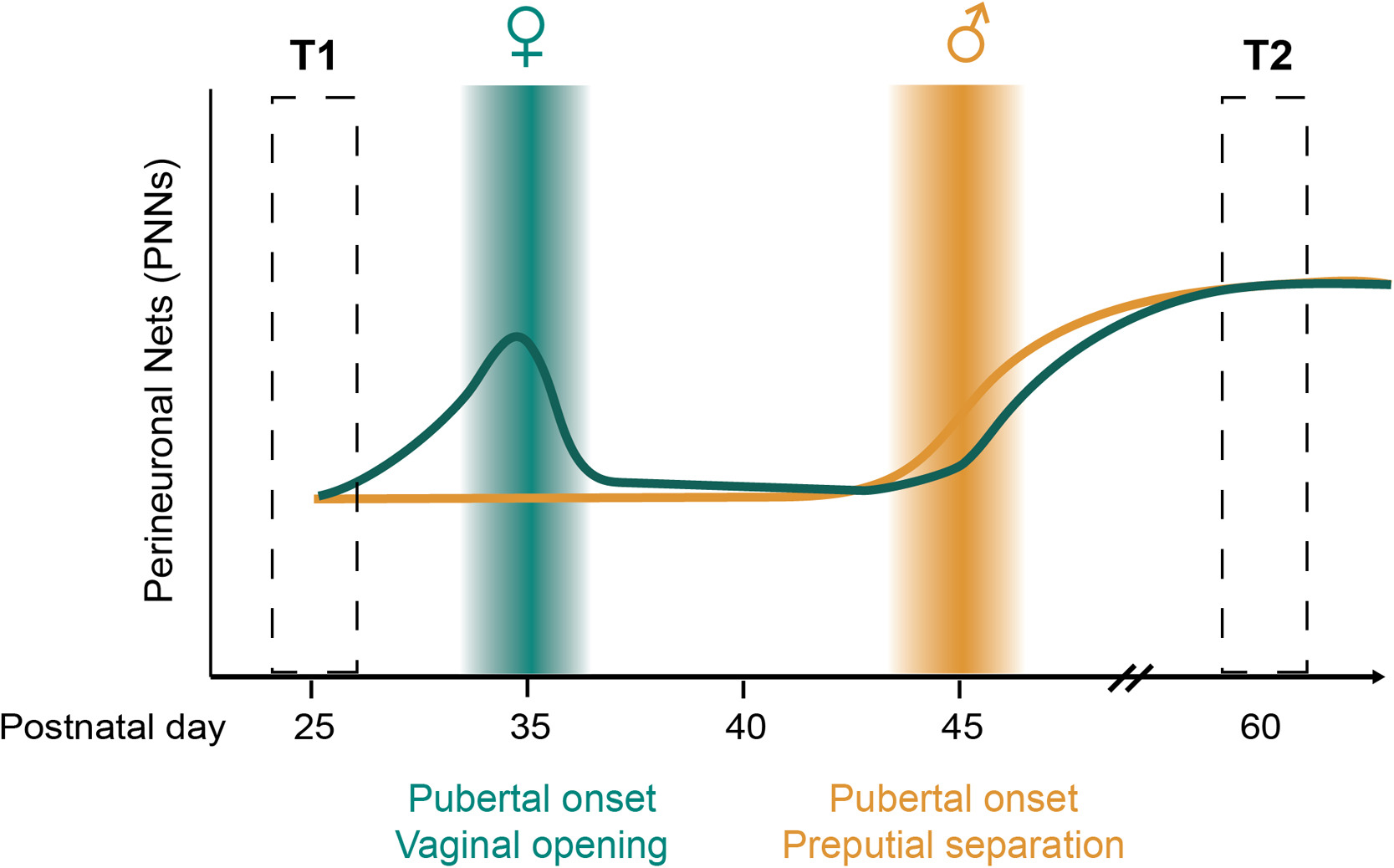
Coming of age in the frontal cortex: The role of puberty in cortical maturation
Across species, adolescence is a period of growing independence that is associated with the maturation of cognitive, social, and affective processing. Reorganization of neural circuits within the frontal cortex is believed to contribute to the emergence of adolescent changes in cognition and behavior. While puberty coincides with adolescence, relatively little is known about which aspects of frontal cortex maturation are driven by pubertal development and gonadal hormones. In this review, we highlight existing work that suggests puberty plays a role in the maturation of specific cell types in the medial prefrontal cortex (mPFC) […]
Learning Rates Are Not All the Same: The Interpretation of Computational Model Parameters Depends on the Context
Reinforcement Learning (RL) has revolutionized the cognitive and brain sciences, explaining behavior from simple conditioning to problem solving, across the life span, and anchored in brain function. However, discrepancies in results are increasingly apparent between studies, particularly in the developmental literature. To better understand these, we investigated to which extent parameters generalize between tasks and models, and capture specific and uniquely interpretable (neuro)cognitive processes. 291 participants aged 8-30 years completed three learning tasks in a single session, and were fitted using state-of-the-art RL models. RL decision noise/exploration parameters generalized well between tasks, decreasing between ages 8-17. Learning rates for negative feedback […]
What do Reinforcement Learning Models Measure? Interpreting Model Parameters in Cognition and Neuroscience
Reinforcement learning (RL) is a concept that has been invaluable to research fields including machine learning, neuroscience, and cognitive science. However, what RL entails partly differs between fields, leading to difficulties when interpreting and translating findings.
This paper lays out these differences and zooms in on cognitive (neuro)science, revealing that we often overinterpret RL modeling results, with severe consequences for future research. Specifically, researchers often assume—implicitly—that model parameters generalize between tasks, models, and participant populations, despite overwhelming negative empirical evidence for this assumption. We also often assume that parameters measure specific, unique, and meaningful (neuro)cognitive processes, a concept we call interpretability, for which […]
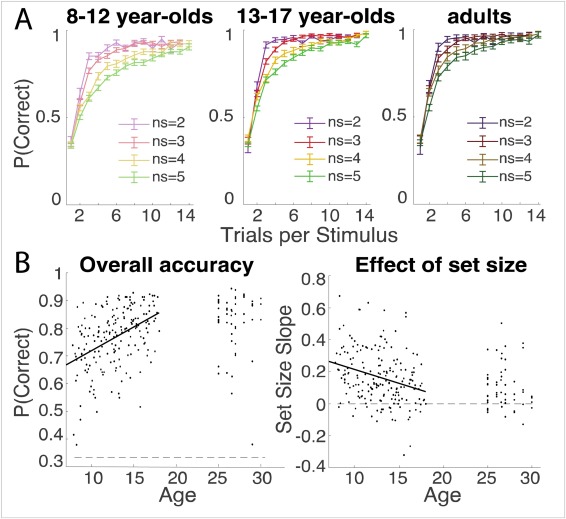
The Unique Advantage of Adolescents in Probabilistic Reversal: Reinforcement Learning and Bayesian Inference Provide Adequate and Complementary Models
During adolescence, youth venture out, explore the wider world, and are challenged to learn how to navigate novel and uncertain environments. We investigated whether adolescents are uniquely adapted to this transition, compared to younger children and adults. In a stochastic, volatile reversal learning task with a sample of 291 participants aged 8-30, we found that adolescents 13-15 years old outperformed both younger and older participants. We developed two independent cognitive models, one based on Reinforcement learning (RL) and the other Bayesian inference (BI), and used hierarchical Bayesian model fitting to assess developmental changes in underlying cognitive mechanisms. Choice parameters in both […]
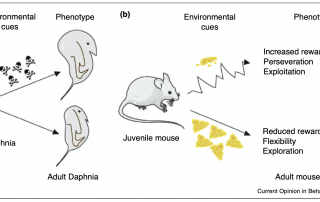
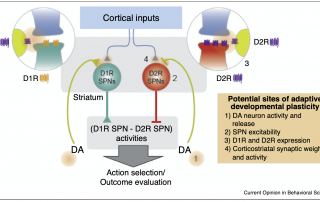
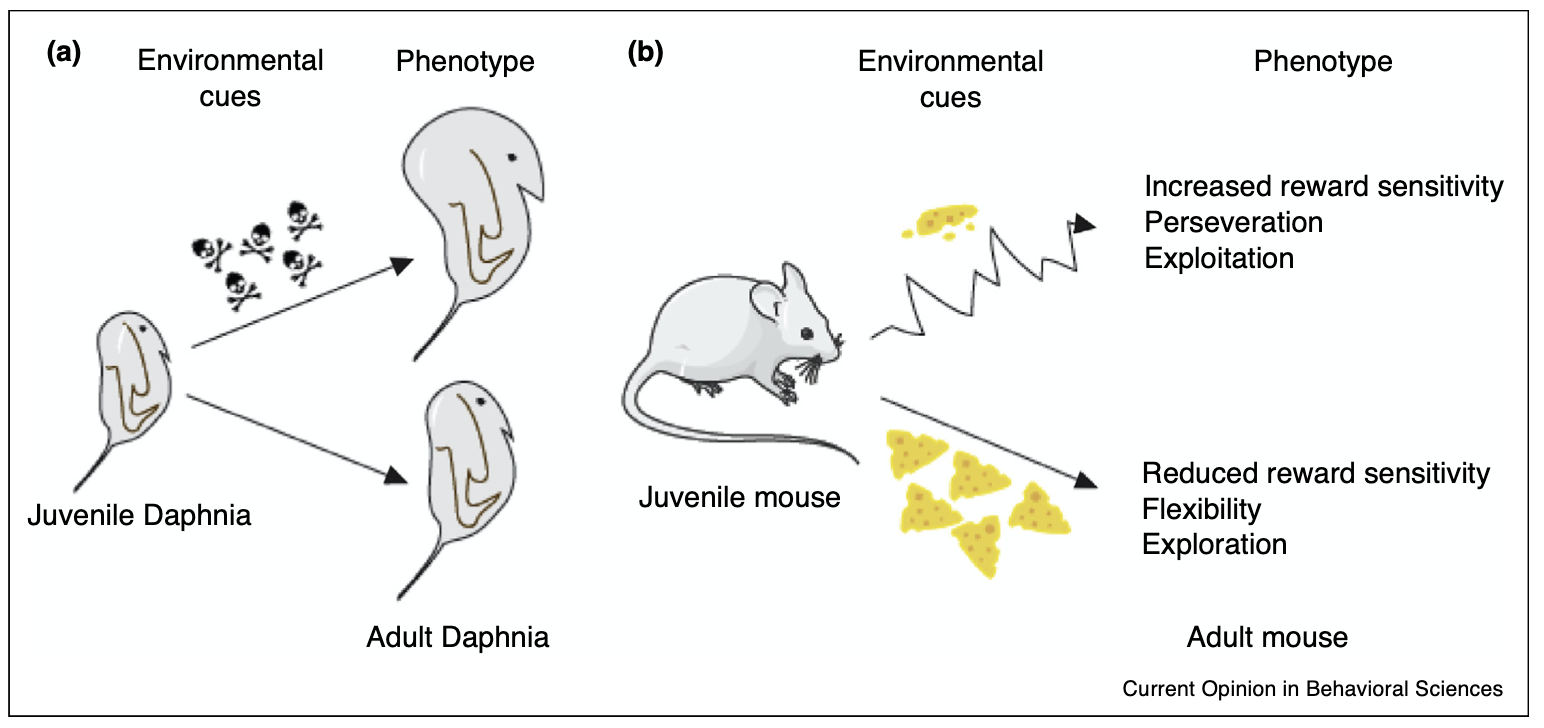
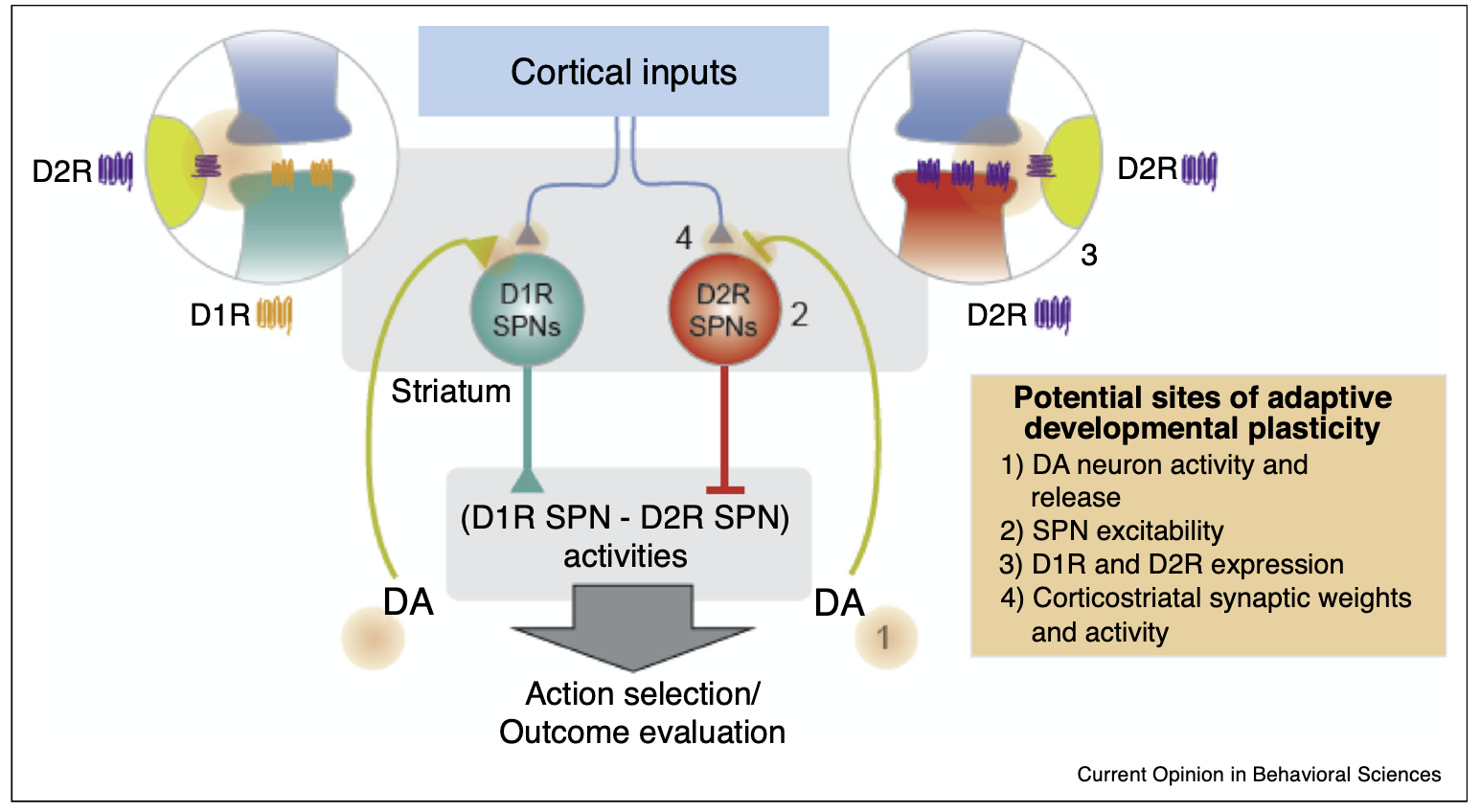
A role for adaptive developmental plasticity in learning and decision making
From both a medical and educational perspective, there is enormous value to understanding the environmental factors that sculpt learning and decision making. These questions are often approached from proximate levels of analysis, but may be further informed by the adaptive developmental plasticity framework used in evolutionary biology. The basic adaptive developmental plasticity framework posits that biological sensitive periods evolved to use information from the environment to sculpt emerging phenotypes. Here, we lay out how we can apply this framework to learning and decision making in the mammalian brain and propose a working model in which dopamine […]
Choice suppression is achieved through opponent but not independent function of the striatal indirect pathway in mice
The dorsomedial striatum (DMS) plays a key role in action selection, but little is known about how direct and indirect pathway spiny projection neurons (dSPNs and iSPNs) contribute to choice suppression in freely moving animals. Here, we used pathway-specific chemogenetic manipulation during a serial choice foraging task to test opposing predictions for iSPN function generated by two theories: 1) the ‘select/suppress’ heuristic which suggests iSPN activity is required to suppress alternate choices and 2) the network-inspired Opponent Actor Learning model (OpAL) which proposes that the weighted difference of dSPN and iSPN activity determines choice. We found that chemogenetic activation, but not […]
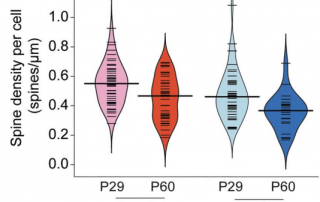
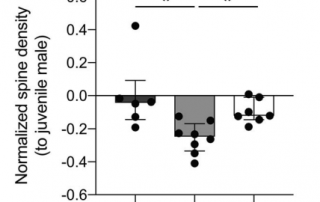
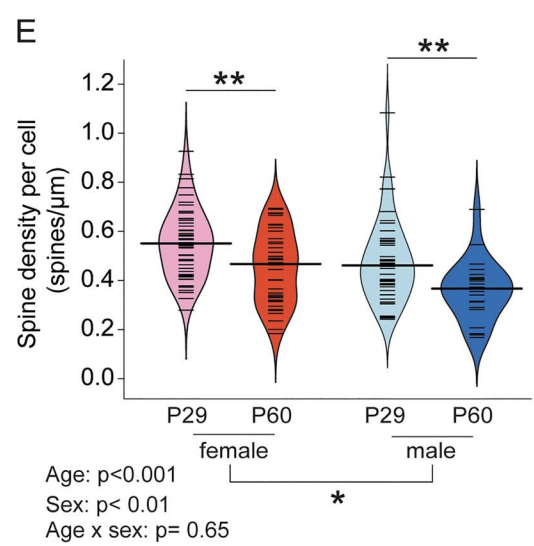
Sex and Pubertal Status Influence Dendritic Spine Density on Frontal Corticostriatal Projection Neurons in Mice
In humans, nonhuman primates, and rodents, the frontal cortices exhibit grey matter thinning and dendritic spine pruning that extends into adolescence. This maturation is believed to support higher cognition but may also confer psychiatric vulnerability during adolescence. Currently, little is known about how specific cell types in the frontal cortex mature or whether puberty plays a role in the maturation of some cell types but not others. Here, we used mice to characterize the spatial topography and adolescent development of cross-corticostriatal (cSTR) neurons that project through the corpus collosum to the dorsomedial striatum. We found that apical spine density on cSTR […]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
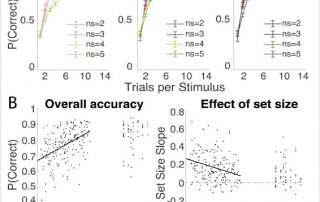
Distentangling the systems contributing to changes in learning during adolescence
Multiple neurocognitive systems contribute simultaneously to learning. For example, dopamine and basal ganglia (BG) systems are thought to support reinforcement learning (RL) by incrementally updating the value of choices, while the prefrontal cortex (PFC) contributes different computations, such as actively maintaining precise information in working memory (WM). It is commonly thought that WM and PFC show more protracted development than RL and BG systems, yet their contributions are rarely assessed in tandem. Here, we used a simple learning task to test how RL and WM contribute to changes in learning across adolescence. We tested 187 subjects ages 8 to 17 and […]