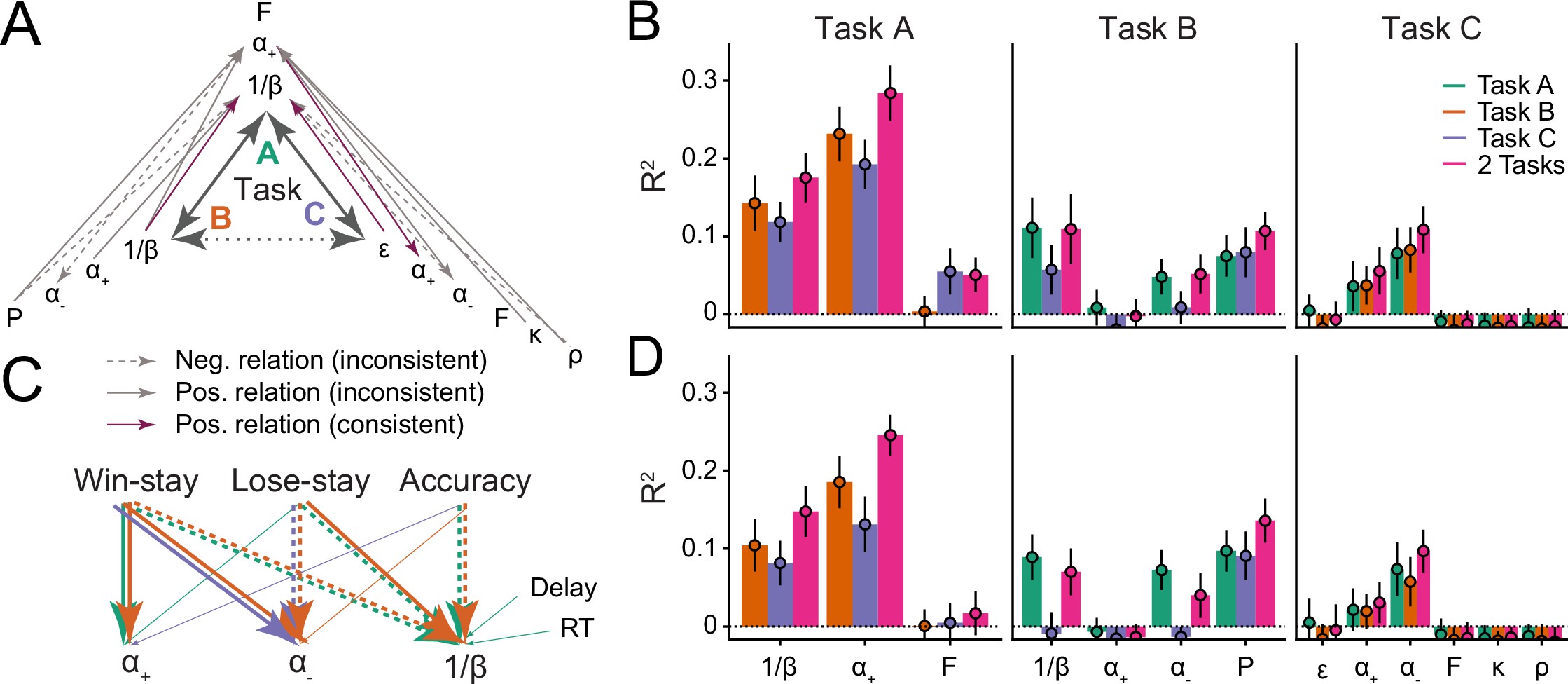
Reinforcement Learning (RL) models have revolutionized the cognitive and brain sciences, promising to explain behavior from simple conditioning to complex problem solving, to shed light on developmental and individual differences, and to anchor cognitive processes in specific brain mechanisms. However, the RL literature increasingly reveals contradictory results, which might cast doubt on these claims. We hypothesized that many contradictions arise from two commonly-held assumptions about computational model parameters that are actually often invalid: That parameters generalize between contexts (e.g. tasks, models) and that they capture interpretable (i.e. unique, distinctive) neurocognitive processes. To test this, we asked 291 participants aged 8–30 years to complete three learning tasks in one experimental session, and fitted RL models to each. We found that some parameters (exploration / decision noise) showed significant generalization: they followed similar developmental trajectories, and were reciprocally predictive between tasks. Still, generalization was significantly below the methodological ceiling. Furthermore, other parameters (learning rates, forgetting) did not show evidence of generalization, and sometimes even opposite developmental trajectories. Interpretability was low for all parameters. We conclude that the systematic study of context factors (e.g. reward stochasticity; task volatility) will be necessary to enhance the generalizability and interpretability of computational cognitive models.
Maria Katharina Eckstein, Sarah L Master, Liyu Xia, Ronald E Dahl, Linda Wilbrecht, Anne GE Collins, The interpretation of computational model parameters depends on the context, eLife (2022) 11:e75474. https://doi.org/10.7554/eLife.75474